Het stof is neergedaald rondom de finishlijn. Zijn jullie ook zo benieuwd naar de getallen?
Het Grote Getal
Ten eerste dat hele grote getal, dat de voorselecteurs, longlist-jury en finalejury altijd de schrik om het hart jaagt: hoeveel woorden hebben de inzenders bij elkaar gepend?
1.248.409 woorden!
Eén miljoen, tweehonderdachtenveertigduizend, vierhonderdnegen woorden!
Demografie
En wie heeft dan al dat schrijfwerk gedaan?
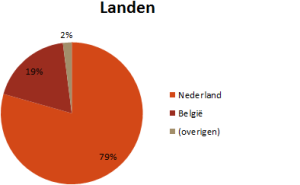
Ten eerste valt op dat ruim driekwart van de deelnemers een Nederlandse postcode heeft. De zuiderburen vertegenwoordigen krap één-vijfde van het deelnemersveld, met nog een handjevol uit andere (Europese) landen.
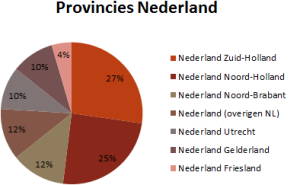
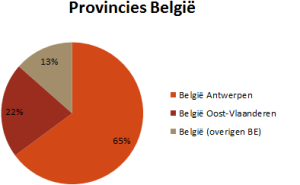
Van die Nederlanders komt weer ruim de helft uit Holland en zijn verder maar vier provincies met méér dan 4 inzendingen vertegenwoordigd. In België zijn zelfs maar twéé provincies significant vertegenwoordigd: Antwerpen en Oost-Vlaanderen zijn goed voor ruim 85% van de Vlaamse inzendingen!
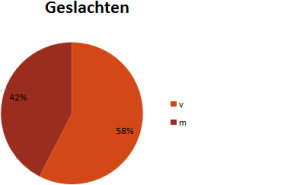
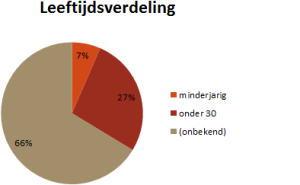
Als we dan in iets meer detail kijken naar de samenstelling van het deelnemersveld, is duidelijk dat de vrouwen de overhand hebben. Bijna 60%! Misschien nog wel opvallender is dat ruim één-derde van de deelnemers zich als Jong Talent wil laten meetellen; 7% was op de deadline zelfs nog minderjarig!
Correlaties
Geen.
Om maar iets te noemen: ik heb eens gekeken of de man/vrouw-verdeling nog verschilt tussen Nederland en België. Helemaal niet! In tegendeel: een chi-kwadraattoets leert dat er geen enkel verschil is tussen de geslachtsverdeling van de Vlaamse en Nederlandse deelnemers (p = 24,5%).
Is er dan een verband tussen Nederland, België en de overige landen in gemiddelde word count van de ingezonden verhalen? Ook al niet! Evenmin als je naar de leeftijdscategorieën kijkt: in elke zichtbare categorie is de gemiddelde verhaallengte ruim boven de 6.000 woorden.
Maar…
Vrouwen Produceren Meer Woorden
Het wordt interessant als we de woordaantallen uitsplitsen naar man en vrouw. Blijven de mannen gemiddeld onder de 6.000 (5.914 om precies te zijn); de vrouwen hebben per verhaal gemiddeld 6.556 woorden nodig! En dit is meer dan een toevallig verschilletje: statistisch gesproken is het een significant verschil (p = 0,3%!).
Concreet? De mannen zijn verantwoordelijk voor 496.766 woorden. En bij elkaar hebben de vrouwelijke deelnemers aan de Paul Harland Prijs 2014 neergepend:
747.394 woorden!
(Nee, dat telt niet op tot 1.248.409, want één deelnemer heeft zijnhaar geslacht niet prijsgegeven…)
Er zijn wat vragen gerezen over deze analyse en hoe die zich verhoudt tot de anonimiteit van de inzenders. Om de anonimiteit te waarborgen bij deze analyse, zijn de volgende maatregelen getroffen:
De lijst waarop de analyse is gebaseerd, is samengesteld door Martijn, die als enige beschikt over alle gegevens van de deelnemers.
De lijst bevat uitsluitend de volgende gegevens van elk ingezonden verhaal: aantal woorden, m/v, land, postcode, en geboortedatum indien bekend. M/v is daarbij vermoedelijk door Martijn afgeleid uit de werkelijke voornamen van de inzenders.
Land is gereduceerd tot Nederland, België en Overig door alle landen met minder dan 5 inzendingen te aggregeren.
Postcode is in twee stappen gereduceerd door eerst alle Nederlandse en Belgische postcodes naar Provincie te vertalen en vervolgens per land de provincies met minder dan 5 inzendingen te aggregeren.
Geboortedatum is gereduceerd tot drie categorieën: onder 18 (minderjarig), onder 30, of onbekend.
Alle statistische analyses zijn gebaseerd op de gereduceerde categorieën zoals hierboven beschreven.
De analyse is uitgevoerd door Floris, wiens rol als voorselecteur al beëindigd was toen hij aan de analyse begon.
Op deze manier is geborgd dat A. de gegevens het oordeel van Floris niet konden beïnvloeden en B. de statistische analyse hierboven op geen enkele manier is te herleiden naar individuele inzendingen, en dat er geen informatie uit te halen is die het oordeel van de longlist- en finalejury kan beïnvloeden.
“De analyse is uitgevoerd door Floris, wiens rol als voorselecteur al beëindigd was toen hij aan de analyse begon.” Zo, jij bent snel door de 202 inzendingen gegaan, Floris! Respect!
En bedankt voor de cijfers! Dat is leuk om te zien/weten.
Leuk, die statistieken over kwantiteiten. Ben ik nu benieuwd naar:
1). Een uitsplitsing over medianen én de modus per grafiek;
2). De statistiek over kwaliteit, ofwel: dezelfde grafieken van hen die door zijn naar de Long list met daarbij het verschil t.o.v. de gehele populatie;
3). Dezelfde ‘eigenschappen’ van de voorselecteurs en dan de eventuele correlatie met de totale populatie én met de populatie die door is (vooral de correlatie tussen geslacht en leeftijd zou interessant kunnen zijn);
4). En dan nog deze zelfde eigenschappen van de juryleden geprognotiseerd op de Long list.
Onderzoeksvragen:
A). ‘Herkent/ sympathiseert’ een voorselecteur/ jurylid een verhaal van een schrijver/ schrijfster met zijn/ haar eigen leeftijd en geslacht? Zo ja, dan bepaalt de selectie van de voorselecteurs/ juryleden (deels) de uitslag
B).Wat zijn de kenmerken waarmee je een kansberekening kunt opstellen of je hoog / laag gaat eindigen?
Andere vragen aan de voorselecteurs:
I). Op basis van welke (kwaliteits)criteria is de Long list bepaald (spanningsboog, plot, taalgebruik, originaliteit, ..??);
II. Hoe scoorden het totaal en de Long list op deze criteria?
III). Wat zijn de verbeterpunten waar jullie tegenaan liepen?
IV). Is er al een Short list gespot?
V). Is de Long list in random volgorde aan de Jury overhandigd?
Leuk leuk leuk! Al zijn de plaatjes wel ietwat aan de kleine kant.
Als ik het goed zie: klopt het dat, ook al is het gemiddelde aantal woorden verschillend tussen vrouwen en mannen, de standaard deviatie van het gemiddelde aantal woorden tussen de twee ongeveer gelijk is?